卓騰語言科技公司服務條款
最後更新日期2024年2月1日
感謝您來到卓騰語言科技網站,本網站係由卓騰語言科技公司 (以下稱「本公司」)提供。當您點選進入本網站、使用本網站或註冊成為本網站之註冊使用者,您將適用卓騰語言科技公司服務條款(下稱「本服務條款」)以及卓騰語言科技股份有限公司隱私權保護政策(本處請置入連結;下稱「本隱私權政策」),因此,請您詳細閱讀本服務條款與本隱私權政策之所有內容,以維護您的權益。當您開始使用本公司之服務(無論是使用無庸登入會員即得使用之線上展示服務,或是註冊會員使得使用之服務),均表示您已經了解並同意遵守本服務條款、本隱私權政策,而此構成您與本公司契約之一部。
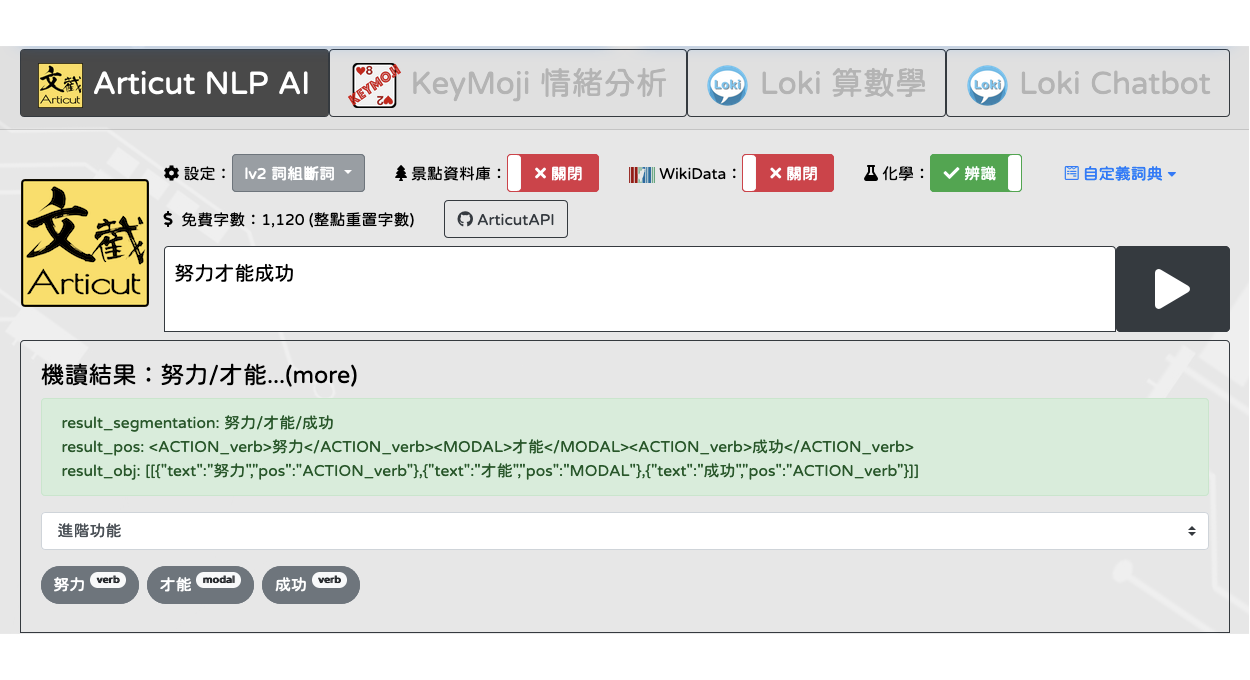
本網站為線上網路平台,提供任何對於語言學、中文斷詞、語音辨識、機器自動語意分析、智慧回饋、自然語言搜尋引擎、文本結構分析等有興趣之人瀏覽、使用。您無須成為本網站之註冊會員即可搜尋或閱覽本網站。然而,若您想要於本網站之討論區開啟議題或參與討論,或是發表或張貼任何評論、建議、討論、連結等,您須成為註冊會員後方得為之。於註冊後您將成為本網站之註冊會員(下稱「註冊會員」),至於未註冊之使用者僅為單純使用者(下稱「單純使用者」)。
倘若您為未滿二十(20)歲,於註冊、購買本公司各項雲端服務前,您的法定代理人(家長或是監護人)亦應閱讀、瞭解並同意本服務條款與本隱私權政策內所有規定,當您註冊、購買本公司各項雲端服務時,即視為您的法定代理人(家長或是監護人)已閱讀、瞭解並同意本服務條款與本隱私權政策內所有規定,以及其後所有變更及/或修改。
一.網站服務使用規定
(ㄧ)倘若您要註冊、購買本公司各項雲端服務時,您應年滿二十歲且具有同意本服務條款及本隱私權政策之法律上能力或取得完全同意或是授權。本公司得本於風險評估而拒絕您申請使用本網站任何一項雲端服務,或是停止您原有的使用權限。您註冊、購買、使用本網站任何一項雲端服務均應遵守您所在地的相關法規(例如民法)以及本服務條款,倘若您為前述行為時候違反您所在地法律,您應自行承擔相關風險與責任。
(二)註冊會員、單純使用者都可以瀏覽、搜尋本公司各項雲端服務內討論區的留言、討論、評論、建議,但是僅有註冊會員才可以在討論區內發表或張貼評論、建議,或是參與討論等。
(三)當您於本網站上著註冊時,您需要提供您的個人資訊予本公司(舉例而言,您的電子郵件),並以您提供的個人資訊內容提供相關服務。請您記得提供正確、完整之個人資訊,並記得當您個人資訊更新時一併將更新之個人資訊提供本公司。本公司對所,如果因您個人資訊不正確、錯誤、未更新而造成損害、損失,或因此導致本公司提供之雲端服務有遺漏、缺失、不足,本公司均不負責。請勿使用您本人以外的其他帳戶、或是使用他人的電子郵件申請本網站之註冊會員。於使用本網站時,您不得宣稱、假扮、號稱或是以任何方式讓第三方誤認、誤會您是本公司人員、或與本公司有特殊關係或關聯。如果本公司發現您註冊時有侵害第三人權利(舉例而言,未取得他人同意而使用他人之電子郵件),本公司得隨時停止、終止您登入本網站,或停止或終止您使用本公司各項雲端服務。
(四)您應對於您於本網站註冊、使用之個人帳號密碼之所有行為承擔責任。如果本公司認為註冊會員提供錯誤、過時或缺漏之個人資訊,或該帳號密碼疑似遭他人冒用或盜用、疑似違反交易安全或本服務條款等情形時,本公司得立即暫停或終止該註冊會員使用本公司雲端服務。如果您發現任何人未取得您的同意或授權而使用您的註冊會員帳戶,應立即通知本公司。另請留意,您不得將註冊會員帳戶為營利目的使用。
(五)本公司透過本網站所提供之各項雲端服務 (包括線上註冊) 僅供自然人及法人使用,若有違反前述規定者而造成本公司損失、損害之情節,本公司有權依法向您主張權利。無論您是註冊會員或單純使用者,當您使用本公司透過本網站所提供的各項服務時,您應遵守中華民國相關法規(包括但不限於民法、著作權法),並應擔保您使用本網站討論區、本公司管理之網際網路社群交流服務空間 (包括但不限於 Blogger, Twitter, Plurk, Facebook) 以及使用本網站服務時之任何行為均符合相關法律規定,例如您應擔保您使用本網站服務或於本網站討論區所輸入、上傳、張貼之一切內容(包括文字、錄音、錄影、連結)均符合相關法律規定。倘若因您的行為違反相關法律規定或侵害第三方權益,您應自行承擔相關責任。
(六)當您使用本公司各項雲端服務時,請遵守台灣與您所在地對於網際網路內容使用與傳輸之規定,倘若發生任何違法情事或有觸犯法令之虞,應由您承擔所有責任,與本公司無涉。倘若您的行為造成本公司、本公司之合作之夥伴受到任何損害或損失,您需對此賠償或補償(包含但不限於訴訟費用及律師費用等)。
(七)請留意,倘若您多次違反本本服務條款或本隱私權政策,本公司有權暫時或永久禁止您使用您的註冊帳戶。
二.智慧財產權利說明
本公司於本網站上提供之所有雲端服務或其相關內容,包括但不限於所有網頁頁面設計、介面、互動功能、URL、電腦程式、圖形、設計、資料庫、軟體、內容、等,以及與此相關之專利權、著作、商標、營業秘密及其他智慧財產權以及資料所有權等,均為本公司或授權本公司使用之人所有。除非事先取得本公司合法書面授權(需代表人簽章)外,任何人皆不得以任何形式模仿、抄襲、擷取、盜用、修改、拷貝、重製、複製、散佈、傳送、展示、表演、發行、授權、進行衍生性創作或基於租用、出售之目的加以使用、利用,且無論是全部或一部,否則應賠償本公司因此所受之所有損害、損失(包含但不限於訴訟費用及律師費用等)。
於您使用本網站任一項雲端服務時,可能會使用到本公司或是第三方授權軟體或資料。惟本公司並未轉讓任何授權軟體或資料之所有權。您保證並同意不會破壞、癱瘓或以任何形式妨礙本網站、本網站任何雲端服務之功能、以及與前述有關之網路或是雲端服務,以致本網站無法使用或是使用上受到限制或影響。
三.使用者隱私權保護
當您瀏覽本公司網站時,並不需要提供您個人資料,但當您願意完成註冊會員操作成為註冊會員、訂閱電子報,或是希望享有本公司為您提供的個人化服務時,本公司將要求您登入註冊會員帳號以方便與您相互聯繫、完成交易、提供服務或處理相關程序。本公司將利用多種方式,透過網站取得您個人資料。取得的管道及應用的範圍將說明如下:
四.服務使用與您的內容
- 本公司不保證於任何時間您均能使用本網站任何一項雲端服務。本網站任何一項雲端服務有可能會在毫無預警之情況下發生中斷、停止、更新或其他無法繼續使用之狀態;此外,本公司也有能決定暫時或永久停止提供任何一項雲端服務或是雲端服務內其中的任何功能。註冊會員與單純使用者均理解且同意,本公司毋庸對於對於前述情形及其所產生之損失、損害成擔任責任。
- 本公司有權對於任何一項雲端服務內容為變更、異動、修改,可能是部份或是全部。您不得因前述服務內容之變更、異動、修改,而要求本公司、本公司之代理人、經理人、受僱人或合作夥伴為任何請求或主張。
本公司遇到下列情況之一時,本公司可能會暫停或永久中斷本網站任何一項雲端服務(可能是全部或一部),惟本公司對於註冊會員或單純使用者因此所受之任何直接或間接損害,皆不負任何賠償或補償之責任:
(a)對相關設備進行例行性或必要之搬遷、更換、升級、保養及維修者
(b)不可抗力之因素(例如戰爭、火災)或不可歸責於本公司之事由所導致之本網站服務停止或中斷
(c)註冊會員或單純使用者有違反政府法令或本服務條款、本隱私權政策等情形
如果您擬於本網站討論區、本公司管理之網際網路社群交流服務空間 (包括但不限於 Blogger, Twitter, Plurk, Facebook)以發表、張貼、回覆討論等形式公開您所搜集、整理、編輯、引用(轉引)、撰寫之內容,您知悉第三方 (包括註冊會員或是單純使用者)均得瀏覽該等內容,且第三方亦可能透過其他網站搜尋而得知您所公開之內容。就前述您所發表、張貼、回覆的公開內容可能無法取消、刪除、撤回、隱藏,您應對於前開內容承擔全部責任(包括但不限於已取得第三方之授權使用、無違反不實廣告等),並應擔保該等內容並無包括任何電腦病毒、木馬或是對於電腦程式或是檔案具有破壞性之資訊。
您擔保並聲明前述由您發表、張貼、回覆的公開內容屬於您單獨創作或已取得他人合法授權,未違反或侵害他人之智慧財產權,亦未違反任何法律規定。您同意無償授權本公司使用、複製、重製、處置、改編、改作、修改、公開發行、傳送、展示及散布前開您的內容,且毋庸支付您或是第三方任何費用或對價;且前開授權係全球的、永久的、非專屬性、可讓渡的、可轉授權、不可撤回的。您並同意本公司得公開展示、重新編排、修改、改編、改作、為衍生著作等方式使用前開您的內容;惟本公司使用時應標示您的註冊會員名稱(但若您希望使用您本名,請您另以電子郵件通知本公司)。您理解且同意,本公司得因應當地法律規定,於特定區域或國家中移除您的內容中所涉及之特定資訊或說明,您授權本公司得自行裁量決定,而毋庸另外通知或取得您的同意。本條所提及之授權,不因您終止、停止或是不再使用本公司、本網站之服務,或是因本服務條款終止而無效或失其效力。
無論您係於本網站討論區、本公司管理之網際網路社群交流服務空間 (包括但不限於 Blogger, Twitter, Plurk, Facebook)以發表、張貼、回覆討論等形式公開您所搜集、整理、編輯、引用(轉引)、撰寫之內容,或是以其他聯繫方式將您的建議或改善方案等通知本公司(包括紙本郵件、電子郵件、傳真、訊息等),您均理解且知悉,本公司有可能正在討論、開發與您的內容或通知內容相同或是類似之計畫或方案(可能是全部或一部),亦可能因收到您的內容或通知內容後而擬著手與您的內容或通知相同或類似之計畫或方案(可能是全部或一部),然而,除本公司另外以書面通知您外,您無權且同意放棄向本公司請求、主張任何之酬勞、報酬、價金、補償、賠償金。其次,本公司對於您提供之建議或是改善方案,並無保密之義務。本條約定,不因您終止、停止或是不再使用本公司、本網站之服務,或是因本服務條款終止而無效或失其效力。
五.免責聲明與責任限制
本公司所提供之服務皆已提供長期且適量之試用期。如因使用本公司的任何服務而致生之損害,本公司不負任何損害賠償責任。惟當使用者願意主動報告服務內容之錯誤時,本公司將儘速確認處理。
即使本服務條款、本隱私權政策內有明確提醒或說明,然而,本公司對於註冊會員、單純使用者於使用本網站各項雲端服務所生之直接或間接之損害,不負賠償或補償責任。
本網站係依當時之功能及現況提供相關產品與服務。本公司不保證、亦未明示或默示本網路上各項雲端服務涉及之內容一定能夠符合註冊會員、單純使用者之需求、要求,包括但不限於速度、安全性、穩定性、完整性、正確性、無瑕疵以及連線不中斷等。
本公司網站之服務串接生成模型功能後,因本公司並非串接後所生成之內容服務提供者,本公司不對所串接之 ChatGPT 或其他生成模型之內容及使用者使用本產品串接其他軟體後因所串接軟體內容修改所生之結果負責。
六.註銷會員資格、數據資料回寄服務及退費
若您因故想要註銷在本公司網站的註冊會員資格並取消所有服務時,即使婉惜,我們仍十分樂意在您願意支付工本費及運費的前提下,將您在本公司網站、伺服器及資料庫中的數據資料燒錄成光碟並寄送給您,並在您確認收迄後,將您在本公司網站及伺服器中所擁有的數據資料全部刪除以維護您的隱私。
當您於本網站完成付費並開始使用本公司的線上任一項雲端服務後,在確認您的使用額度已經開始消耗的前提下,我們將不予退費。
若您於本網站完成付費後,在開始使用您所購買的使用額度前想辦理退費的話,我們將在扣除 10% 的手續費後,將費用利用線上匯款的方式退回到您指定的銀行帳戶。
七.增修服務條款內容
本公司有權隨時單方變更或修改本服務條款、本隱私權政策之全部或一部之內容,且於本網頁首頁上公告後立即生效。本公司將於每次更新時於本網站首頁公告發布訊息,倘若您為註冊會員本公司將透過您註冊會員時留下的電子郵件傳遞新版服務條款內容給您。您理解且同意,當您進入、點選或使用本網站即立即適用本服務條款與本隱私權政策,其後您每次造訪時,請留意本服務條款及本隱私權政策之最新版本內容。若您拒絕同意本服務條款、本隱私權政策之變更或修正,請立即關閉並離開本網站,否則視為您同意修改或變更後之最新版本。
八.其他規定
- 本公司保留修改、變更、終止本網站任一項雲端服務的權利,且無須任何理由、無庸事前通知、亦不因此承擔任何賠償或補償責任。
- 本服務條款與本隱私權政策構成當事人間完整且最後之合意,並取代任何以往口頭或書面之協商、合意、承諾及了解。
- 倘若本服務條款、本隱私權政策有任一條款無法執行或被認定無效,其餘部分仍為有效,且因此不受影響。
- 除事前取得本公司書面同意外,本服務條款、本隱私權政策不得轉讓。此外,註冊會員不得將註冊帳號移轉、讓與給第三人。
- 本服務條款、本隱私權政策,悉以中華民國法令為準據法。因註冊會員、單純使用者使用本網站之任一項雲端服務、或因本服務條款及/或本隱私權政策所發生之爭議,應以善意先行協商解決;倘仍無法解決,除法律另有強制規定者外,悉以台灣台北地方法院為第一審管轄法院。
- 本服務條款、本隱私權政策有中英文兩款。當兩者發生歧義或版本落差時,以中文版為主。